
Рекурсия и рекурсивные алгоритмы |
|
Рекурсией называется ситуация, когда подпрограмма вызывает сама себя. Впервые сталкиваясь с такой алгоритмической конструкцией, большинство людей испытывает определенные трудности, однако немного практики и рекурсия станет понятным и очень полезным инструментом в вашем программистском арсенале. Содержание1. Сущность рекурсииПроцедура или функция может содержать вызов других процедур или функций. В том числе процедура может вызвать саму себя. Никакого парадокса здесь нет – компьютер лишь последовательно выполняет встретившиеся ему в программе команды и, если встречается вызов процедуры, просто начинает выполнять эту процедуру. Без разницы, какая процедура дала команду это делать. Пример рекурсивной процедуры: procedure Rec(a: integer);
begin
if a>0 then
Rec(a-1);
writeln(a);
end;
Рассмотрим, что произойдет, если в основной программе поставить вызов, например, вида Rec(3). Ниже представлена блок-схема, показывающая последовательность выполнения операторов.  Рис. 1. Блок схема работы рекурсивной процедуры. Процедура Rec вызывается с параметром a = 3. В ней содержится вызов процедуры Rec с параметром a = 2. Предыдущий вызов еще не завершился, поэтому можете представить себе, что создается еще одна процедура и до окончания ее работы первая свою работу не заканчивает. Процесс вызова заканчивается, когда параметр a = 0. В этот момент одновременно выполняются 4 экземпляра процедуры. Количество одновременно выполняемых процедур называют глубиной рекурсии. Четвертая вызванная процедура (Rec(0)) напечатает число 0 и закончит свою работу. После этого управление возвращается к процедуре, которая ее вызвала (Rec(1)) и печатается число 1. И так далее пока не завершатся все процедуры. Результатом исходного вызова будет печать четырех чисел: 0, 1, 2, 3. Еще один визуальный образ происходящего представлен на рис. 2. 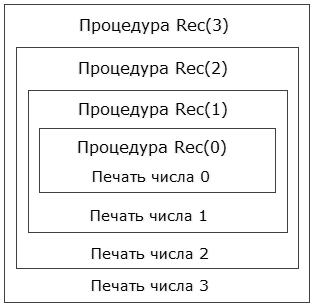 Рис. 2. Выполнение процедуры Rec с параметром 3 состоит из выполнения процедуры Rec с параметром 2 и печати числа 3. В свою очередь выполнение процедуры Rec с параметром 2 состоит из выполнения процедуры Rec с параметром 1 и печати числа 2. И т. д. В качестве самостоятельного упражнения подумайте, что получится при вызове Rec(4). Также подумайте, что получится при вызове описанной ниже процедуры Rec2(4), где операторы поменялись местами. procedure Rec2(a: integer);
begin
writeln(a);
if a>0 then
Rec2(a-1);
end;
Обратите внимание, что в приведенных примерах рекурсивный вызов стоит внутри условного оператора. Это необходимое условие для того, чтобы рекурсия когда-нибудь закончилась. Также обратите внимание, что сама себя процедура вызывает с другим параметром, не таким, с каким была вызвана она сама. Если в процедуре не используются глобальные переменные, то это также необходимо, чтобы рекурсия не продолжалась до бесконечности. 2. Сложная рекурсияВозможна чуть более сложная схема: функция A вызывает функцию B, а та в свою очередь вызывает A. Это называется сложной рекурсией. При этом оказывается, что описываемая первой процедура должна вызывать еще не описанную. Чтобы это было возможно, требуется использовать опережающее описание. Пример:
procedure A(n: integer); {Опережающее описание (заголовок) первой процедуры}
procedure B(n: integer); {Опережающее описание второй процедуры}
procedure A(n: integer); {Полное описание процедуры A}
begin
writeln(n);
B(n-1);
end;
procedure B(n: integer); {Полное описание процедуры B}
begin
writeln(n);
if n<10 then
A(n+2);
end;
Опережающее описание процедуры B позволяет вызывать ее из процедуры A. Опережающее описание процедуры A в данном примере не требуется и добавлено из эстетических соображений. Если обычную рекурсию можно уподобить уроборосу (рис. 3), то образ сложной рекурсии можно почерпнуть из известного детского стихотворения, где «Волки с перепуга, скушали друг друга». Представьте себе двух съевших друг друга волков, и вы поймете сложную рекурсию.  Рис. 3. Уроборос – змей, пожирающий свой хвост. Рисунок из алхимического трактата «Synosius» Теодора Пелеканоса (1478г).  Рис. 4. Сложная рекурсия. 3. Имитация работы цикла с помощью рекурсииЕсли процедура вызывает сама себя, то, по сути, это приводит к повторному выполнению содержащихся в ней инструкций, что аналогично работе цикла. Некоторые языки программирования не содержат циклических конструкций вовсе, предоставляя программистам организовывать повторения с помощью рекурсии (например, Пролог, где рекурсия - основной прием программирования). Для примера сымитируем работу цикла for. Для этого нам потребуется переменная счетчик шагов, которую можно реализовать, например, как параметр процедуры. Пример 1.
procedure LoopImitation(i, n: integer);
{Первый параметр – счетчик шагов, второй параметр – общее количество шагов}
begin
writeln('Hello N ', i); //Здесь любые инструкции, которые будут повторятся
if i<n then //Пока счетчик цикла не станет равным максимальному
LoopImitation(i+1, n); //значению n, повторяем инструкции путем вызова
//нового экземпляра процедуры
end;
Результатом вызова вида LoopImitation(1, 10) станет десятикратное выполнение инструкций с изменением счетчика от 1 до 10. В данном случае будет напечатано: Hello N 1 Вообще, не трудно видеть, что параметры процедуры это пределы изменения значений счетчика. Можно поменять местами рекурсивный вызов и подлежащие повторению инструкции, как в следующем примере. Пример 2.
procedure LoopImitation2(i, n: integer);
begin
if i<n then
LoopImitation2(i+1, n);
writeln('Hello N ', i);
end;
В этом случае, прежде чем начнут выполняться инструкции, произойдет рекурсивный вызов процедуры. Новый экземпляр процедуры также, прежде всего, вызовет еще один экземпляр и так далее, пока не дойдем до максимального значения счетчика. Только после этого последняя из вызванных процедур выполнит свои инструкции, затем выполнит свои инструкции предпоследняя и т.д. Результатом вызова LoopImitation2(1, 10) будет печать приветствий в обратном порядке: Hello N 10 Если представить себе цепочку из рекурсивно вызванных процедур, то в примере 1 мы проходим ее от раньше вызванных процедур к более поздним. В примере 2 наоборот от более поздних к ранним. Наконец, рекурсивный вызов можно расположить между двумя блоками инструкций. Например:
procedure LoopImitation3(i, n: integer);
begin
writeln('Hello N ', i); {Здесь может располагаться первый блок инструкций}
if i<n then
LoopImitation3(i+1, n);
writeln('Hello N ', i); {Здесь может располагаться второй блок инструкций}
end;
Здесь сначала последовательно выполнятся инструкции из первого блока затем в обратном порядке инструкции второго блока. При вызове LoopImitation3(1, 10) получим: Hello N 1 Потребуется сразу два цикла, чтобы сделать то же самое без рекурсии. Тем, что выполнение частей одной и той же процедуры разнесено по времени можно воспользоваться. Например: Пример 3: Перевод числа в двоичную систему. Получение цифр двоичного числа, как известно, происходит с помощью деления с остатком на основание системы счисления 2. Если есть число
Взяв же целую часть от деления на 2:
получим число, имеющее то же двоичное представление, но без последней цифры. Таким образом, достаточно повторять приведенные две операции пока поле очередного деления не получим целую часть равную 0. Без рекурсии это будет выглядеть так: while x>0 do begin c:=x mod 2; x:=x div 2; write(c); end; Проблема здесь в том, что цифры двоичного представления вычисляются в обратном порядке (сначала последние). Чтобы напечатать число в нормальном виде придется запомнить все цифры в элементах массива и выводить в отдельном цикле. С помощью рекурсии нетрудно добиться вывода в правильном порядке без массива и второго цикла. А именно:
procedure BinaryRepresentation(x: integer);
var
c, x: integer;
begin
{Первый блок. Выполняется в порядке вызова процедур}
c := x mod 2;
x := x div 2;
{Рекурсивный вызов}
if x>0 then
BinaryRepresentation(x);
{Второй блок. Выполняется в обратном порядке}
write(c);
end;
Вообще говоря, никакого выигрыша мы не получили. Цифры двоичного представления хранятся в локальных переменных, которые свои для каждого работающего экземпляра рекурсивной процедуры. То есть, память сэкономить не удалось. Даже наоборот, тратим лишнюю память на хранение многих локальных переменных x. Тем не менее, такое решение кажется мне красивым. 4. Рекуррентные соотношения. Рекурсия и итерацияГоворят, что последовательность векторов ~~~~~(1)") Простым примером величины, вычисляемой с помощью рекуррентных соотношений, является факториал  Очередной факториал ! \cdot n~~~~~(2)") Введя обозначение ") Вектора x := 1; for i := 2 to n do x := x * i; writeln(x); Каждое такое обновление (x := x * i) называется итерацией, а процесс повторения итераций – итерированием. Обратим, однако, внимание, что соотношение (1) является чисто рекурсивным определением последовательности и вычисление n-го элемента есть на самом деле многократное взятие функции f от самой себя: ))}_n}~~~~~(4)") В частности для факториала можно написать:
function Factorial(n: integer): integer;
begin
if n > 1 then
Factorial := n * Factorial(n-1)
else
Factorial := 1;
end;
Следует понимать, что вызов функций влечет за собой некоторые дополнительные накладные расходы, поэтому первый вариант вычисления факториала будет несколько более быстрым. Вообще итерационные решения работают быстрее рекурсивных. Прежде чем переходить к ситуациям, когда рекурсия полезна, обратим внимание еще на один пример, где ее использовать не следует. Рассмотрим частный случай рекуррентных соотношений, когда следующее значение в последовательности зависит не от одного, а сразу от нескольких предыдущих значений. Примером может служить известная последовательность Фибоначчи, в которой каждый следующий элемент есть сумма двух предыдущих: ") При «лобовом» подходе можно написать:
function Fib(n: integer): integer;
begin
if n > 1 then
Fib := Fib(n-1) + Fib(n-2)
else
Fib := 1;
end;
Каждый вызов Fib создает сразу две копии себя, каждая из копий – еще две и т.д. Количество операций растет с номером n экспоненциально, хотя при итерационном решении достаточно линейного по n количества операций. На самом деле, приведенный пример учит нас не КОГДА рекурсию не следует использовать, а тому КАК ее не следует использовать. В конце концов, если существует быстрое итерационное (на базе циклов) решение, то тот же цикл можно реализовать с помощью рекурсивной процедуры или функции. Например:
// x1, x2 – начальные условия (1, 1)
// n – номер требуемого числа Фибоначчи
function Fib(x1, x2, n: integer): integer;
var
x3: integer;
begin
if n > 1 then
begin
x3 := x2 + x1;
x1 := x2;
x2 := x3;
Fib := Fib(x1, x2, n-1);
end else
Fib := x2;
end;
И все же итерационные решения предпочтительны. Спрашивается, когда же в таком случае, следует пользоваться рекурсией? Любые рекурсивные процедуры и функции, содержащие всего один рекурсивный вызов самих себя, легко заменяются итерационными циклами. Чтобы получить что-то, не имеющее простого нерекурсивного аналога, следует обратиться к процедурам и функциям, вызывающим себя два и более раз. В этом случае множество вызываемых процедур образует уже не цепочку, как на рис. 1, а целое дерево. Существуют широкие классы задач, когда вычислительный процесс должен быть организован именно таким образом. Как раз для них рекурсия будет наиболее простым и естественным способом решения. 5. ДеревьяТеоретической базой для рекурсивных функций, вызывающих себя более одного раза, служит раздел дискретной математики, изучающий деревья. 5.1. Основные определения. Способы изображения деревьевОпределение: Деревом будем называть конечное множество T, состоящее из одного или более узлов, таких что: Это определение является рекурсивным. Если коротко, то дерево это множество, состоящее из корня и присоединенных к нему поддеревьев, которые тоже являются деревьями. Дерево определяется через само себя. Однако данное определение осмысленно, так как рекурсия конечна. Каждое поддерево содержит меньше узлов, чем содержащее его дерево. В конце концов, мы приходим к поддеревьям, содержащим всего один узел, а это уже понятно, что такое.  Рис. 3. Дерево. На рис. 3 показано дерево с семью узлами. Хотя обычные деревья растут снизу вверх, рисовать их принято наоборот. При рисовании схемы от руки такой способ, очевидно, удобнее. Из-за данной несогласованности иногда возникает путаница, когда говорят о том, что один из узлов находится над или под другим. По этой причине удобнее пользоваться терминологией, употребляемой при описании генеалогических деревьев, называя более близкие к корню узлы предками, а более далекие потомками. Узлы, не содержащие поддеревьев, называются концевыми узлами или листьями. Множество не пересекающихся деревьев называется лесом. Например, лес образуют поддеревья, исходящие из одного узла. Графически дерево можно изобразить и некоторыми другими способами. Некоторые из них представлены на рис. 4. Согласно определению дерево представляет собой систему вложенных множеств, где эти множества или не пересекаются или полностью содержатся одно в другом. Такие множества можно изобразить как области на плоскости (рис. 4а). На рис. 4б вложенные множества располагаются не на плоскости, а вытянуты в одну линию. Рис. 4б также можно рассматривать как схему некоторой алгебраической формулы, содержащей вложенные скобки. Рис. 4в дает еще один популярный способ изображения древовидной структуры в виде уступчатого списка. 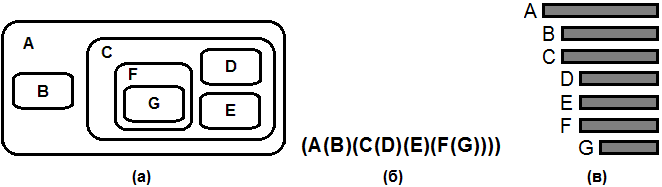 Рис. 4. Другие способы изображения древовидных структур: (а) вложенные множества; (б) вложенные скобки; (в) уступчатый список. Уступчатый список имеет очевидное сходство со способом форматирования программного кода. Действительно, программа, написанная в рамках парадигмы структурного программирования, может быть представлена как дерево, состоящее из вложенных друг в друга конструкций. Также можно провести аналогию между уступчатым списком и внешним видом оглавлений в книгах, где разделы содержат подразделы, те в свою очередь поподразделы и т.д. Традиционный способ нумерации таких разделов (раздел 1, подразделы 1.1 и 1.2, подподраздел 1.1.2 и т.п.) называется десятичной системой Дьюи. В применении к дереву на рис. 3 и 4 эта система даст: 1. A; 1.1 B; 1.2 C; 1.2.1 D; 1.2.2 E; 1.2.3 F; 1.2.3.1 G; 5.2. Прохождение деревьевВо всех алгоритмах, связанных с древовидными структурами неизменно встречается одна и та же идея, а именно идея прохождения или обхода дерева. Это – такой способ посещения узлов дерева, при котором каждый узел проходится точно один раз. При этом получается линейная расстановка узлов дерева. В частности существует три способа: можно проходить узлы в прямом, обратном и концевом порядке. Алгоритм обхода в прямом порядке:
Данный алгоритм рекурсивен, так как прохождение дерева содержит прохождение поддеревьев, а они в свою очередь проходятся по тому же алгоритму. В частности для дерева на рис. 3 и 4 прямой обход дает последовательность узлов: A, B, C, D, E, F, G. Получающаяся последовательность соответствует последовательному слева направо перечислению узлов при представлении дерева с помощью вложенных скобок и в десятичной системе Дьюи, а также проходу сверху вниз при представлении в виде уступчатого списка. При реализации этого алгоритма на языке программирования попадание в корень соответствует выполнение процедурой или функцией некоторых действий, а прохождение поддеревьев – рекурсивным вызовам самой себя. В частности для бинарного дерева (где из каждого узла исходит не более двух поддеревьев) соответствующая процедура будет выглядеть так:
// Preorder Traversal – английское название для прямого порядка
procedure PreorderTraversal({Аргументы});
begin
//Прохождение корня
DoSomething({Аргументы});
//Прохождение левого поддерева
if {Существует левое поддерево} then
PreorderTransversal({Аргументы 2});
//Прохождение правого поддерева
if {Существует правое поддерево} then
PreorderTransversal({Аргументы 3});
end;
То есть сначала процедура производит все действия, а только затем происходят все рекурсивные вызовы. Алгоритм обхода в обратном порядке:
То есть проходятся все поддеревья слева на право, а возвращение в корень располагается между этими прохождениями. Для дерева на рис. 3 и 4 это дает последовательность узлов: B, A, D, C, E, G, F. В соответствующей рекурсивной процедуре действия будут располагаться в промежутках между рекурсивными вызовами. В частности для бинарного дерева:
// Inorder Traversal – английское название для обратного порядка
procedure InorderTraversal({Аргументы});
begin
//Прохождение левого поддерева
if {Существует левое поддерево} then
InorderTraversal({Аргументы 2});
//Прохождение корня
DoSomething({Аргументы});
//Прохождение правого поддерева
if {Существует правое поддерево} then
InorderTraversal({Аргументы 3});
end;
Алгоритм обхода в концевом порядке:
Для дерева на рис. 3 и 4 это даст последовательность узлов: B, D, E, G, F, C, A. В соответствующей рекурсивной процедуре действия будут располагаться после рекурсивных вызовов. В частности для бинарного дерева:
// Postorder Traversal – английское название для концевого порядка
procedure PostorderTraversal({Аргументы});
begin
//Прохождение левого поддерева
if {Существует левое поддерево} then
PostorderTraversal({Аргументы 2});
//Прохождение правого поддерева
if {Существует правое поддерево} then
PostorderTraversal({Аргументы 3});
//Прохождение корня
DoSomething({Аргументы});
end;
5.3. Представление дерева в памяти компьютераЕсли некоторая информация располагается в узлах дерева, то для ее хранения можно использовать соответствующую динамическую структуру данных. На Паскале это делается с помощью переменной типа запись (record), содержащей указатели на поддеревья того же типа. Например, бинарное дерево, где в каждом узле содержится целое число можно сохранить с помощью переменной типа PTree, который описан ниже:
type
PTree = ^TTree;
TTree = record
Inf: integer;
LeftSubTree, RightSubTree: PTree;
end;
Каждый узел имеет тип PTree. Это указатель, то есть каждый узел необходимо создавать, вызывая для него процедуру New. Если узел является концевым, то его полям LeftSubTree и RightSubTree присваивается значение nil. В противном случае узлы LeftSubTree и RightSubTree также создаются процедурой New. Схематично одна такая запись изображена на рис. 5. 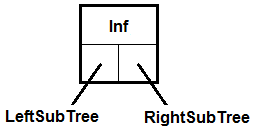 Рис. 5. Схематичное изображение записи типа TTree. Запись имеет три поля: Inf – некоторое число, LeftSubTree и RightSubTree – указатели на записи того же типа TTree. Пример дерева, составленного из таких записей, показан на рисунке 6.  Рис. 6. Дерево, составленное из записей типа TTree. Каждая запись хранит число и два указателя, которые могут содержать либо nil, либо адреса других записей того же типа. Если вы ранее не работали со структурами состоящими из записей, содержащих ссылки на записи того же типа, то рекомендуем ознакомиться с материалом о рекурсивных структурах данных. 6. Примеры рекурсивных алгоритмов6.1. Рисование дереваРассмотрим алгоритм рисования деревца, изображенного на рис. 6. Если каждую линию считать узлом, то данное изображение вполне удовлетворяет определению дерева, данному в предыдущем разделе.  Рис. 6. Деревце. Рекурсивная процедура, очевидно должна рисовать одну линию (ствол до первого разветвления), а затем вызывать сама себя для рисования двух поддеревьев. Поддеревья отличаются от содержащего их дерева координатами начальной точки, углом поворота, длиной ствола и количеством содержащихся в них разветвлений (на одно меньше). Все эти отличия следует сделать параметрами рекурсивной процедуры. Пример такой процедуры, написанный на Delphi, представлен ниже:
procedure Tree(
Canvas: TCanvas; //Canvas, на котором будет рисоваться дерево
x,y: extended; //Координаты корня
Angle: extended; //Угол, под которым растет дерево
TrunkLength: extended; //Длина ствола
n: integer //Количество разветвлений (сколько еще предстоит
//рекурсивных вызовов)
);
var
x2, y2: extended; //Конец ствола (точка разветвления)
begin
x2 := x + TrunkLength * cos(Angle);
y2 := y - TrunkLength * sin(Angle);
Canvas.MoveTo(round(x), round(y));
Canvas.LineTo(round(x2), round(y2));
if n > 1 then
begin
Tree(Canvas, x2, y2, Angle+Pi/4, 0.55*TrunkLength, n-1);
Tree(Canvas, x2, y2, Angle-Pi/4, 0.55*TrunkLength, n-1);
end;
end;
Для получения рис. 6 эта процедура была вызвана со следующими параметрами: Tree(Image1.Canvas, 175, 325, Pi/2, 120, 15); Заметим, что рисование осуществляется до рекурсивных вызовов, то есть дерево рисуется в прямом порядке. 6.2. Ханойские башниСогласно легенде в Великом храме города Бенарас, под собором, отмечающим середину мира, находится бронзовый диск, на котором укреплены 3 алмазных стержня, высотой в один локоть и толщиной с пчелу. Давным-давно, в самом начале времен монахи этого монастыря провинились перед богом Брамой. Разгневанный, Брама воздвиг три высоких стержня и на один из них поместил 64 диска из чистого золота, причем так, что каждый меньший диск лежит на большем. Как только все 64 диска будут переложены со стержня, на который Бог Брама сложил их при создании мира, на другой стержень, башня вместе с храмом обратятся в пыль и под громовые раскаты погибнет мир. Независимо от Брамы данную головоломку в конце 19 века предложил французский математик Эдуард Люка. В продаваемом варианте обычно использовалось 7-8 дисков (рис. 7). 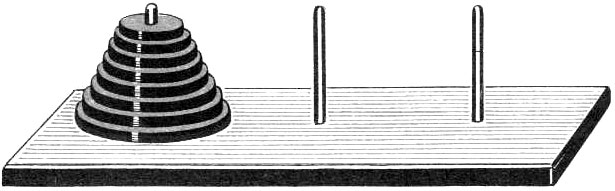 Рис. 7. Головоломка «Ханойские башни». Предположим, что существует решение для n-1 диска. Тогда для перекладывания n дисков надо действовать следующим образом: 1) Перекладываем n-1 диск. Поскольку для случая n = 1 алгоритм перекладывания очевиден, то по индукции с помощью выполнения действий (1) – (3) можем переложить произвольное количество дисков. Создадим рекурсивную процедуру, печатающую всю последовательность перекладываний для заданного количества дисков. Такая процедура при каждом своем вызове должна печатать информацию об одном перекладывании (из пункта 2 алгоритма). Для перекладываний из пунктов (1) и (3) процедура вызовет сама себя с уменьшенным на единицу количеством дисков.
//n – количество дисков
//a, b, c – номера штырьков. Перекладывание производится со штырька a,
//на штырек b при вспомогательном штырьке c.
procedure Hanoi(n, a, b, c: integer);
begin
if n > 1 then
begin
Hanoi(n-1, a, c, b);
writeln(a, ' -> ', b);
Hanoi(n-1, c, b, a);
end else
writeln(a, ' -> ', b);
end;
Заметим, что множество рекурсивно вызванных процедур в данном случае образует дерево, проходимое в обратном порядке. 6.3. Синтаксический анализ арифметических выраженийЗадача синтаксического анализа заключается в том, чтобы по имеющейся строке, содержащей арифметическое выражение, и известным значениям, входящих в нее переменных, вычислить значение выражения. Процесс вычисления арифметических выражений можно представить в виде бинарного дерева. Действительно, каждый из арифметических операторов (+, –, *, /) требует двух операндов, которые также будут являться арифметическими выражениями и, соответственно могут рассматриваться как поддеревья. Рис. 8 показывает пример дерева, соответствующего выражению: ~~~~~(6)") 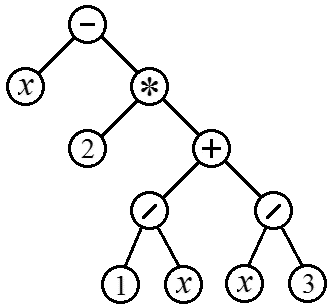 Рис. 8. Синтаксическое дерево, соответствующее арифметическому выражению (6). В таком дереве концевыми узлами всегда будут переменные (здесь x) или числовые константы, а все внутренние узлы будут содержать арифметические операторы. Чтобы выполнить оператор, надо сначала вычислить его операнды. Таким образом, дерево на рисунке следует обходить в концевом порядке. Соответствующая последовательность узлов ") называется обратной польской записью арифметического выражения. При построении синтаксического дерева следует обратить внимание на следующую особенность. Если есть, например, выражение ") и операции сложения и вычитания мы будем считывать слева на право, то правильное синтаксическое дерево будет содержать минус вместо плюса (рис. 9а). По сути, это дерево соответствует выражению Аналогично справа налево нужно анализировать выражения, содержащие операторы умножения и деления.  Рис. 9. Синтаксические деревья для выражения a – b + c при чтении слева направо (а) и справа налево (б). В файле SynAn.pas приведен пример функции, вычисляющей значения выражений, содержащих только одну переменную x. Дадим краткое описание реализованного там алгоритма:
Заметим, что в данном примере вычисления производятся одновременно с анализом строкового выражения. Это приводит к тому, что для некоторых выражений вычисления могут происходить в 100 – 1000 раз медленнее, чем, если бы эти выражения были скомпилированы как часть программы. Если одно и то же выражение требуется вычислить много раз при различных значения переменных, то следует разделить анализ строки и вычисления. Такой подход может позволить ускорить вычисления в сотни раз. Результатом анализа строки должна быть последовательность узлов дерева в концевом порядке. Каждый узел должен хранить информацию о подузлах и о той операции, которая в нем совершается. Например, узлы можно реализовать в виде записей, одно из полей который имеет процедурный тип. Другой вариант – каждый узел это объект, где операция реализована как виртуальный метод. 6.4. Быстрые сортировкиПростые методы сортировки вроде метода выбора или метода пузырька сортируют массив из n элементов за O(n2) операций. Однако с помощью принципа «разделяй и властвуй» удается построить более быстрые, работающие за O(n log2 n) алгоритмы. Суть этого принципа в том, что решение получается путем рекурсивного разделения задачи на несколько простые подзадачи того же типа до тех пор, пока они не станут элементарными. Приведем в качестве примеров несколько быстрых алгоритмов такого рода. Алгоритм 1: «Быстрая» сортировка (quicksort). 1. Выбирается опорный элемент (например, первый или случайный). 2. Реорганизуем массив так, чтобы сначала шли элементы меньшие опорного, потом равные ему, затем большие. Для этого достаточно помнить, сколько было найдено меньших (m1) и больших (m2), чем опорный и ставить очередной элемент на место с индексом m1, а очередной больший на место с индексом n-1-m2. После выполнения такой операции опорный элемент и равные ему стоят на своем месте, их переставлять больше не придется. Между «меньшей» и «большей» часть массива перестановок также быть не может. То есть эти части можно сортировать независимо друг от друга. 3. Если «меньшая» или «большая» часть состоит из одного элемента, то она уже отсортирована и делать ничего не надо. Иначе сортируем эти части с помощью алгоритма быстрой сортировки (то есть, выполняем для нее шаги 1-3). Как видите, быстрая сортировка состоит из выполнения шагов 1 и 2 и рекурсивного вызова алгоритма для получившихся частей массива. Алгоритм 2: Сортировка слиянием (merge sort).
Алгоритм 3: Сортировка деревом (tree sort). Прежде чем переходить к объяснению сути алгоритма введем одно понятие. Двоичным деревом поиска называется бинарное дерево, в узлах которого располагаются числа таким образом, что в левом поддереве каждого узла находятся числа меньшие, чем в этом узле, а в правом поддереве больше или равные тому, что в этом узле. На рис. 10 показано два примера деревьев поиска, составленных из одних и тех же чисел.  Рис. 10. Двоичные деревья поиска, составленные из чисел 1, 3, 4, 6, 7, 8, 10, 13, 14. Если для каждой вершины высота поддеревьев различается не более чем на единицу, то дерево называется сбалансированным. Сбалансированные деревья поиска также называются АВЛ-деревьями (по первым буквам фамилий изобретателей Г. М. Адельсона-Вельского и Е. М. Ландиса). Как видно на рис. 10а показано сбалансированное дерево, на рис. 10б несбалансированное. Заметим, что расположение чисел по возрастанию получится, если обходить эти деревья в обратном прядке. Сортировка деревом получится, если мы сначала последовательно будем добавлять числа из массива в двоичное дерево поиска, а затем обойдем его в обратном порядке. Если дерево будет близко к сбалансированному, то сортировка потребует примерно n log2 n операций. Если не повезет и дерево окажется максимально несбалансированным, то сортировка займет n2 операций. 6.5. Произвольное количество вложенных цикловРазместив рекурсивные вызовы внутри цикла, по сути, получим вложенные циклы, где уровень вложенности равен глубине рекурсии. Для примера напишем процедуру, печатающую все возможные сочетания из k чисел от 1 до n (
for i1 := 1 to n do
for i2 := i1 + 1 to n do
writeln(i1, ' ', i2);
Сочетания из трех чисел (k=3) так:
for i1 := 1 to n do
for i2 := i1 + 1 to n do
for i3 := i2 + 1 to n do
writeln(i1, ' ', i2, ' ', i3);
Однако, если количество чисел в сочетании задается переменной, то придется прибегнуть к рекурсии.
procedure Combinations(
n, k: integer;
//Массив, в котором будем формировать сочетания
var Indexes: array of integer;
//Счетчик глубины рекурсии
d: integer);
var
i, i_min: integer;
s: string;
begin
if d < k then
begin
if d = 0 then
i_min := 1
else
i_min := Indexes[d-1] + 1;
for i := i_min to n do
begin
Indexes[d] := i;
Combinations(n, k, Indexes, d+1);
end;
end
else
begin
for i := 0 to k-1 do
write(Indexes[i], ' ');
writeln;
end;
end;
6.6. Задачи на графахГрафом называют графическое изображение, состоящее из вершин (узлов) и соединяющих некоторые пары вершин ребер (рис. 11а). Более строго: граф – совокупность множества вершин и множества ребер. Множество ребер – подмножество евклидова квадрата множества вершин (то есть ребро соединяет ровно две вершины). Ребрам можно также присвоить направление. Граф в этом случае называется ориетированным (рис. 11б).  Рис. 11. (а) Граф. (б) Ориентированный граф. Теория графов находит применения в самых разных областях. Несколько примеров:
Современная теория графов представляет собой мощную формальную систему, имеющую необозримое множество применений. Путем или цепью в графе называется последовательность вершин, в которой каждая вершина соединена ребром со следующей. Пути, в которых начальная и конечная вершина совпадают, называют циклами. Если для каждой пары вершин существует путь их соединяющих, то такой граф называют связным. В программировании используются три способа хранения в памяти информации о стуктуре графов. 1) Матрицы смежности Квадратная матрица M, где как строки, так и столбцы соответствуют вершинам графа. Если вершины с номерами i и j соединены ребром, то Mij = 1, иначе Mij = 0. Для неориентированного графа матрица, очевидно, симметрична. Ориентированный граф задается антисимметричной матрицей. Если ребро выходит из узла i и приходит в узел j, то Mij = 1, а симметричный элемент Mji = -1. 2) Матрица инцидентности Столбцы матрицы соответствуют вершинам, а строки ребрам. Если ребро с номером i соединяет вершины с номерами j и k, то элементы матрицы Iij = Iik = 1. Остальные элементы i-й строки равны 0. 3) Список ребер Просто набор пар номеров вершин, соединенных ребрами. Рассмотренные выше деревья являются частным случаем графов. Деревом будет любой связный граф, не содержащий циклов. Задачи, возникающие в теории графов многочисленны и разнообразны. Про них пишутся толстые книги, и нет никакой возможности сколько-нибудь полно их здесь обозреть. Поэтому мы ограничимся замечанием, что многие из этих задач требуют систематического перебора вершин. Если перебирать вершины, связанные ребрами и при этом посещать каждую вершину только один раз, то множество посещаемых алгоритмом вершин будет образовывать дерево, а сам алгоритм естественно сделать рекурсивным. Например, классической задачей является поиск пути из одной вершины в другую. Алгоритм поиска должен будет построить дерево возможных путей из начальной вершины, концевыми узлами которого будут вершины, из которых нельзя попасть ни в какую вершину, не принадлежащую ранее построенной ветви (не помеченную как уже посещенную). Задача будет решена, когда один из концевых узлов совпадет с конечной вершиной, путь в которую требуется найти. 6.7. ФракталыФракталами называют геометрические фигуры, обладающие свойством самоподобия, то есть состоящие из частей, подобных всей фигуре. Классическим примером является кривая Коха, построение которой показано на рис. 12. Изначально берется отрезок прямой (рис. 12а). Он делится на три части, средняя часть изымается и вместо нее строится угол (рис. 12б), стороны которого равны длине изъятого отрезка (то есть 1/3 от длины исходного отрезка). Такая операция повторяется с каждым из получившихся 4-х отрезков (рис. 12в). И так далее (рис. 12г). Кривая Коха получается после бесконечного числа таких итераций. На практике построение можно прекратить, когда размер деталей окажется меньше разрешения экрана (рис. 12д).  Рис. 12. Процесс построения кривой Коха. Еще одним примером может служить деревце на рис. 6. Оно также содержит части, подобные всему дереву в целом, что делает его фракталом. Фракталы, по сути, рекурсивные структуры и их построение естественно производить с помощью рекурсивных процедур. 7. Избавление от рекурсииЛюбой рекурсивный алгоритм может быть переписан без использования рекурсии. Заметим, что быстродействие алгоритмов при избавлении от рекурсии, как правило, повышается. Еще одной причиной чтобы избавиться от рекурсии является ограничение на объем хранимых программой локальных переменных и значений параметров одновременно выполняющихся процедур. При очень глубокой рекурсии этот объем возрастает, и программа перестает работать, выдавая ошибку «Stack overflow» (переполнение стека). Так почему же люди продолжают пользоваться рекурсивными алгоритмами? Очевидно, потому что это проще и естественнее, чем соответствующие нерекурсивные решения. Тем не менее, знание о способах обойтись без рекурсии необходимо. Ниже представлено несколько вариантов того, как это можно сделать. 7.1. Явное использование стекаСтеком называется структура данных, в которой добавление и извлечение данных происходит с одного конца, называемого вершиной стека (рис. 13). Наглядным образом стека может служить стопка тарелок – добавлять или забрать тарелки можно только сверху. Каждая тарелка соответствует элементу данных.  Рис. 13. Наглядное представление стека. Push (проталкивание) – традиционное название для операции добавления данных в стек, Pop (выталкивание) – традиционное название для операции извлечения данных из стека. Когда одна процедура или функция вызывает другую, то параметры первой процедуры, а также место, с которого ее выполнение должно продолжиться после того как отработает вызванная процедура (точка возврата), запоминаются в так называемом стеке вызовов. Если вызванная процедура в свою очередь чего-нибудь вызывает, то ее параметры и точка возврата также добавляются в стек. При рекурсивных вызовах стек вызовов хранит цепочку из данных об одновременно работающих процедурах. Во всех продвинутых средах разработки эту цепочку вместе с запомненными параметрами процедур можно просмотреть во время отладки. Соответствующая команда обычно называется “Call Stack” (в Delphi ей соответствует сочетание клавиш Ctrl – Alt – S). Универсальный способ избавиться от рекурсии – это самостоятельно запрограммировать те действия со стеком, которые фактически происходят, когда вы используете рекурсивные вызовы. Покажем, как это можно сделать, на примере дважды вызывающей себя рекурсивной процедуры. Для начала реализуем в виде класса стек, хранящий параметры процедуры:
type
//Запись для хранения параметров процедур
Parameters = record
//Список параметров
end;
//Стек удобно реализовать с помощью связанных списков
//(http://www.tvd-home.ru/prog/16_4)
PList = ^List;
List = record
Data: Parameters;
Next: PList;
end;
//Описанный одновсязанный список соединим с методами
//добавления и удаления элементов и получим стек.
Stack = class
private
StackTop: PList;
public
//Добавление данных
procedure Push(NewData: Parameters);
//Извлечение данных
function Pop: Parameters;
//Проверка наличия данных
function Empty: boolean;
end;
implementation
//Добавление данных
procedure Stack.Push(NewData: Parameters);
var
NewElement: PList;
begin
New(NewElement);
NewElement^.Data := NewData;
NewElement^.Next := StackTop;
StackTop := NewElement;
end;
//Извлечение данных
function Stack.Pop: Parameters;
var
PopedElement: PList;
begin
PopedElement := StackTop;
StackTop := StackTop^.Next;
Pop := PopedElement^.Data;
Dispose(PopedElement);
end;
//Проверка наличия данных
function Stack.Empty: boolean;
begin
Empty := StackTop = nil;
end;
Рассмотрим обобщенную рекурсивную процедуру с двумя вызовами самой себя.
procedure Recurs(P1: Parameters);
begin
DoSomething(P1);
if <условие> then
begin
P2 := F(P1);
Recurs(P2);
P3 := G(P1);
Recurs(P3);
end;
end;
В данной процедуре некоторые действия (DoSomething) выполняются много раз при разных значениях параметров. Нерекурсивный аналог должен хранить эти параметры в стеке. Каждый рекурсивный вызов будет соответствовать добавлению очередных параметров в стек. Вместо рекурсии появляется цикл, который выполняется, пока в стеке есть необработанные параметры.
procedure NonRecurs(P1: Parameters);
var
S: Stack;
P: Parameters;
begin
S := Stack.Create;
S.Push(P1);
while not S.Empty do
begin
P1 := S.Pop;
DoSomething(P1);
if <условие> then
begin
P3 := G(P1);
S.Push(P3);
P2 := F(P1);
S.Push(P2);
end;
end;
end;
Обратите внимание, что рекурсивные вызовы шли сначала для параметров P2, потом для P3. В нерекурсивной процедуре в стек отправляются сначала параметры P3, а только потом P2. Это связано с тем, что при рекурсивных вызовах в стек, по сути, отправляется недовыполненная часть процедуры, которая в нашем случае содержит вызов Recurs(P3). Упомянутой выше перестановки можно избежать, если вместо стека использовать очередь – структуру данных, где добавление и извлечение элементов происходит с разных концов. Это будет некоторым отступлением от точной имитации процессов при рекурсивных вызовах. Однако в данном примере это кажется более удобным: каждый рекурсивный вызов будет прямо заменяться добавлением параметров в очередь. 7.2. Запоминание последовательности рекурсивных вызововКак говорилось выше, рекурсивные вызовы образуют дерево, где каждый узел соответствует вызову одной процедуры. Последовательность выполнения этих процедур соответствует тому или иному алгоритму обхода узлов. Если требуется много раз обойти узлы одного и того же дерева, то можно один раз обойти их рекурсивно, запомнить количество и последовательность узлов, а затем, пользуясь этой информацией, обходить узлы уже нерекурсивно. Например, в разделе 6.3 обсуждалась задача вычисления арифметических выражений, заданных строкой. Может возникнуть ситуация, когда одно и то же выражение потребуется вычислить много раз при различных значениях переменной x. Синтаксическое дерево, которое требуется обходить при таких вычислениях, не зависит от x. Можно обойти его один раз, построив при этом массив, где каждый элемент будет соответствовать узлу дерева, а их последовательность – порядку обхода. Повторные вычисления при новом x потребуют только нерекурсивного перебора элементов массива. Еще один пример такого запоминания в задаче о вычислении значений многомерных полиномов смотрите тут: http://tvd-home.ru/numerical/polynom. Такой подход не избавляет нас от рекурсии полностью. Однако он позволяет ограничиться только одним обращением к рекурсивной процедуре, что может быть достаточно, если мотивом является забота о максимальной производительности. 7.3. Определение узла дерева по его номеруИдея данного подхода в том, чтобы заменить рекурсивные вызовы простым циклом, который выполнится столько раз, сколько узлов в дереве, образованном рекурсивными процедурами. Что именно будет делаться на каждом шаге, следует определить по номеру шага. Сопоставить номер шага и необходимые действия – задача не тривиальная и в каждом случае ее придется решать отдельно. Например, пусть требуется выполнить k вложенных циклов по n шагов в каждом:
for i1 := 0 to n-1 do
for i2 := 0 to n-1 do
for i3 := 0 to n-1 do
…
Если k заранее неизвестно, то написать их явным образом, как показано выше невозможно. Используя прием, продемонстрированный в разделе 6.5 можно получить требуемое количество вложенных циклов с помощью рекурсивной процедуры:
procedure NestedCycles(Indexes: array of integer; n, k, depth: integer);
var
i: integer;
begin
if depth <= k then
for i:=0 to n-1 do
begin
Indexes[depth] := i;
NestedCycles(Indexes, n, k, depth + 1);
end
else
DoSomething(Indexes);
end;
Чтобы избавиться от рекурсии и свести все к одному циклу, обратим внимание, что если нумеровать шаги в системе счисления с основанием n, то каждый шаг имеет номер, состоящий из цифр i1, i2, i3, … или соответствующих значений из массива Indexes. То есть цифры соответствуют значениям счетчиков циклов. Номер шага в обычной десятичной системе счисления: ") Всего шагов будет nk. Перебрав их номера в десятичной системе счисления и переведя каждый из них в систему с основанием n, получим значения индексов:
M := round(IntPower(n, k));
for i := 0 to M-1 do
begin
Number := i;
for p := 0 to k-1 do
begin
Indexes[k – p] := Number mod n;
Number := Number div n;
end;
DoSomething(Indexes);
end;
Еще раз отметим, что метод не универсален и под каждую задачу придется придумывать что-то свое. Еще один замечательный пример - вычисление по номеру шага перекладываний в задаче о Ханойских башнях смотрите тут: http://algolist.manual.ru/maths/combinat/hanoi.php Контрольные вопросы1. Определите, что сделают приведенные ниже рекурсивные процедуры и функции. (а) Что напечатает приведенная ниже процедура при вызове Rec(4)?
procedure Rec(a: integer);
begin
writeln(a);
if a>0 then
Rec(a-1);
writeln(a);
end;
(б) Чему будет равно значение функции Nod(78, 26)?
function Nod(a, b: integer): integer;
begin
if a > b then
Nod := Nod(a – b, b)
else
if b > a then
Nod := Nod(a, b – a)
else
Nod := a;
end;
(в) Что будет напечатано приведенными ниже процедурами при вызове A(1)? procedure A(n: integer); procedure B(n: integer); procedure A(n: integer); begin writeln(n); B(n-1); end; procedure B(n: integer); begin writeln(n); if n < 5 then A(n+2); end; (г) Что напечатает нижеприведенная процедура при вызове BT(0, 1, 3)?
procedure BT(x: real; D, MaxD: integer);
begin
if D = MaxD then
writeln(x)
else
begin
BT(x – 1, D + 1, MaxD);
BT(x + 1, D + 1, MaxD);
end;
end;
2. Уроборос – змей, пожирающий собственный хвост (рис. 14) в развернутом виде имеет длину L, диаметр около головы D, толщину брюшной стенки d. Определите, сколько хвоста он сможет в себя впихнуть и в сколько слоев после этого будет уложен хвост?  Рис. 14. Развернутый уроборос. 3. Для дерева на рис. 10а укажите последовательности посещения узлов при прямом, обратном и концевом порядке обхода. 4. Изобразите графически дерево, заданное с помощью вложенных скобок: (A(B(C, D), E), F, G). 5. Изобразите графически синтаксическое дерево для следующего арифметического выражения: +1/x") Запишите это выражение в обратной польской записи. 6. Для приведенного ниже графа (рис. 15) запишите матрицу смежности и матрицу инцидентности.  Рис. 15. Задачи1. Вычислив факториал достаточно большое количество раз (миллион или больше), сравните эффективность рекурсивного и итерационного алгоритмов. Во сколько раз будет отличаться время выполнения и как это отношение будет зависеть от числа, факториал которого рассчитывается? 2. Напишите рекурсивную функцию, проверяющую правильность расстановки скобок в строке. При правильной расстановке выполняются условия: (а) количество открывающих и закрывающих скобок равно. Примеры неправильной расстановки: )(, ())(, ())(() и т.п. 3. В строке могут присутствовать скобки как круглые, так и квадратные скобки. Каждой открывающей скобке соответствует закрывающая того же типа (круглой – круглая, квадратной- квадратная). Напишите рекурсивную функцию, проверяющую правильность расстановки скобок в этом случае. Пример неправильной расстановки: ( [ ) ]. 4. Число правильных скобочных структур длины 6 равно 5: ()()(), (())(), ()(()), ((())), (()()). Указание: Правильная скобочная структура минимальной длины «()». Структуры большей длины получаются из структур меньшей длины, двумя способами: (а) если меньшую структуру взять в скобки, 5. Создайте процедуру, печатающую все возможные перестановки для целых чисел от 1 до N. 6. Создайте процедуру, печатающую все подмножества множества {1, 2, …, N}. 7. Создайте процедуру, печатающую все возможные представления натурального числа N в виде суммы других натуральных чисел. 8. Создайте функцию, подсчитывающую сумму элементов массива по следующему алгоритму: массив делится пополам, подсчитываются и складываются суммы элементов в каждой половине. Сумма элементов в половине массива подсчитывается по тому же алгоритму, то есть снова путем деления пополам. Деления происходят, пока в получившихся кусках массива не окажется по одному элементу и вычисление суммы, соответственно, не станет тривиальным. Замечание: Данный алгоритм является альтернативой приему накопления суммы. В случае вещественнозначных массивов он, обычно, позволяет получать меньшие погрешности округления. 9. Запрограммируйте быстрые методы сортировки массивов, описанные в разделе 6.4. 10. Создайте процедуру, рисующую кривую Коха (рис. 12). 11. Воспроизведите рис. 16. На рисунке на каждой следующей итерации окружности в 2.5 раза меньше (этот коэффициент можно сделать параметром).  Рис. 16. Литература1. Д. Кнут. Искусство программирования на ЭВМ. т. 1. (раздел 2.3. «Деревья»). Другие материалы на этом сайтеБлизкие разделы учебника по программированию: Рекуррентные соотношения Вычисление полиномов от нескольких переменных - еще один пример рекурсивного алгоритма.
|
|
|
Персональная страничка
| |
|
|
 , то его последняя цифра в его двоичном представлении равна
, то его последняя цифра в его двоичном представлении равна .
. ,
, задана рекуррентным соотношением, если задан начальный вектор
задана рекуррентным соотношением, если задан начальный вектор ") и функциональная зависимость последующего вектора от предыдущего
и функциональная зависимость последующего вектора от предыдущего
 , получим соотношение:
, получим соотношение: из формулы (1) можно интерпретировать как наборы значений переменных. Тогда вычисление требуемого элемента последовательности будет состоять в повторяющемся обновлении их значений. В частности для факториала:
из формулы (1) можно интерпретировать как наборы значений переменных. Тогда вычисление требуемого элемента последовательности будет состоять в повторяющемся обновлении их значений. В частности для факториала: попарно непересекающихся подмножествах
попарно непересекающихся подмножествах  , каждое из которых в свою очередь является деревом. Деревья
, каждое из которых в свою очередь является деревом. Деревья .") Облегчить составление дерева можно, если анализировать выражение (8) наоборот, справа налево. В этом случае получается дерево с рис. 9б, эквивалентное дереву 8а, но не требующее замены знаков.
Облегчить составление дерева можно, если анализировать выражение (8) наоборот, справа налево. В этом случае получается дерево с рис. 9б, эквивалентное дереву 8а, но не требующее замены знаков. ). Числа, входящие в каждое сочетание, будем печатать в порядке возрастания. Сочетания из двух чисел (k=2) печатаются так:
). Числа, входящие в каждое сочетание, будем печатать в порядке возрастания. Сочетания из двух чисел (k=2) печатаются так:|
Copyright 2010 by Dikanev Taras
|
|
Прочитал, что на некоторых функциональных языках задача разложения рекурсии в цикл решается на уровне компилятора. Говорят, что так сделано в Erlang.
Очень интересно представлн материал: образно и понятно. Спасибо!
Очень понятное изложение материала. Огромное спасибо!
Класс! Очень толково.
Интересное представление материала. Очень полезно и занимательно. СПАСИБО
Здраствуте я поддерживаю выше сказаное, можно у вас попросить о помощи?, мне нужен код программы или исходник, на курсовую работу, времени мало на подготовку и я просто не смогу усвоить весь материал за короткое время, программа на тему «рекурсивный алгоритм поиска в массивах данных» Пожалуйста
не понятен образ рекурсии «змей пожирающий свой хвост» и про двух волков…немного ясно становится первое объяснение с rec(a),далее если оператор writeln(a)ставим перед if (rec2(a))ничего не меняется ,идет вывод цифр в том же порядке-в чем фишка? не написано для чего нужна рекурсия,то же самое можно делать с иттерацией не переполняя память или как?
Очень интересный и точный материал! Спасибо!
Материал супер. Узнал кое-что новое, хоть и с рекурсией дружу уже 2 года.
2 дня не мог написать функцию, а просто нужно было ещё раз почитать про суть подхода. Спасибо за доступное и полезное изложение материала.
Огромное спасибо! Все разжевано и понятно. Идеальный материал для студентов.
Юрию «не понятен образ рекурсии «змей пожирающий свой хвост» и про двух волков…»
С образами рекурсии сложно, да. Они не объяснять должны, а давать образную картинку. Про двух волков… Может, будет интереснее так:«За что же, не боясь греха, кукушка хвалит петуха? За то, что хвалит он кукушку»
Тарас Викторович, большое спасибо.Тема рекурсии включена в демоверсии ЕГЭ по информатике и очень актуальна. А вот изложения материала в доступной и понятной форме мало.
В примере с функциями loop_imitation(i, n) выводиться будут значения до 11 включительно.
Спасибо, исправил.
Это оптимизация называется хвостовая рекурсия. Она встроена во все современые компиляторы. Так что если у вас процедура или функция вызывает сама себя всего 1 раз скорей всего она будет превращена в цикл на уровне машинных команд (асм) или уровне байткода. Точнее даже раньше на уровне внутренеего представления вашей проги — объектных команд компирятора.
Цикл на erlang (как вариант):
%% =================================
cycle_1_cycle(F,I, N2, Step) ->
case (I = ok;
true ->
F(I),
cycle_1_cycle(F,I+Step, N2, Step)
end.
%% Цикл по одной переменной
cycle_1(F, N1, N2, Step) ->
cycle_1_cycle(F, N1, N2, Step).
%% =================================
Пример вызова:
cycle_1(fun(X)-> io:format(«~p~n»,[X]) end, 3,10,1).
Sorry. Как-то странно и непонятно опубликовался текст (выше).
4-я строка сверху должна быть:
case (I _знак_меньше_или_равно_ N2) of
Следующая за ней (почему-то пропущена) должна быть:
false -> ok;
Последняя строка: должны быть двойные кавычки (а не те, что там «нарисовались»)…
Все хорошо. Но как сделать большой файловый стек?
Спасибо вам большое за разжевывание !
Очень внятно изложил всю суть, класс
Лучшего изложения материала по рекурсиям я не встречала. Спасибо!
В частности для дерева на рис. 3 и 4 прямой обход дает последовательность узлов: A, B, C, D, E, G, H.
Отлично изложен материал. У вас похоже здесь ошибка в составе дерева на рис. 3.
Спасибо, Виталий. Исправил.
Очень понятное объяснение! Побольше бы таких материалов!!! Класс!!!
поясните, пожалуйста, новичку такой момент.
Общее правило, что команды выполняются последовательно, сначала первая, затем вторая и т.д. В самом первом примере здесь вначале идет проверка условия if, затем рекурсионный вызов Rec(a-1), а за ним вывод на печать
if a>0 then
Rec(a-1);
writeln(a);
Но если команды выполняются последовательно, то до печати ведь дело не должно дойти, поскольку рекурсионный вызов завернул процесс и снова вызвал функцию, где опять первым пунктом идет проверка условия и за ним снова рекурсионный вызов!?
Почему же тогда команда вывода на печать накапливается в стеке? Ведь по идее она не должна запускаться и поэтому она не может быть незаконченной?
Каждый новый вызов Rec происходит с на единицу меньшим значением параметра. В конце концов параметр окажется равен нулю и тогда новый вызов не произойдет. Дальше последняя вызванная Rec напечатает свой параметр и завершит работу. После этого предпоследняя Rec напечатает параметр и т.д.
и все равно не въезжаю, почему после того, как последняя Rec напечатает свой параметр и завершит работу, почему после этого выполняется предпоследняя команда на печать? Она ведь на запускалась и поэтому не может находиться в стеке, поскольку там хранятся только незавершенные команды, т.е. те которые начаты, но не закончены. А эта предпоследняя команда на печать, как и предыдущие, они не ведь не начинались?
Предпоследняя Rec начала выполнятся. Когда она встретила последний вызов Rec, то оставшаяся невыполненной часть (печать параметра) отправилась в стек. Когда последний вызов Rec завершился, из стека достается эта невыполненная часть и выполняется.
ок, поясните плз в коде, когда именно начинает выполняться предпоследняя и предыдущие перед ней?
if a>0 then
Rec(a-1);
writeln(a);
Ведь здесь четко видно, что вызов Rec выполняется раньше writeln? И что до writeln дело не доходит
В предпоследней Rec будет вызов Rec(0). Он завершится, после этого выполниться writeln.
да, согласен, вызов с Rec(0) завершится и после него выполнится команда writenln. Здесь как раз-таки все понятно.
Но почему после этого начнут выполняться предыдущие whriteln? Ведь по идее их не должно быть в стеке?
Как я пытался показать в предыдущем комментарии, Rec(a-1) расположен в коде раньше, чем whriteln. Поэтому вначале выполняется Rec(a-1) и он заворачивает процесс к началу функции. И в этом случае по идее до команды whrieln дело не доходит, т.е. она не выполняется. А если она не выполняется, то она и не останавливается, не прерывается. Следовательно она и не должна попадать в стек!
Т.е. whriteln может выполниться только один раз, когда происходит вызов Rec(0) и после этого всё!
Сорри, что может быть напрягаю, но уже зациклился on this point и не могу понять, где ошибка в этих рассуждениях?
Каждый раз, когда одна функция вызывает другую, ее состояние (локальные переменные, значения параметров) и точка, где такой вызов произошел, отправляются в стек.
Вызываем Rec(1). Он доходит до вызова Rec(0), отправляет в стек значение параметра (a = 1), и место с которого надо продолжить выполнение (сразу после вызова Rec(0)). Только после этого начинается выполнение Rec(0). Когда Rec(0) закончилась, из стека достается инфа, что a = 1 и надо выполнять код Rec(1) после вызова Rec(0).
все прозрел!)) вот оно, решение!))
Получается, что здесь есть еще одна, третья операция, а именно — запись в стек.
Т.е. перед вызовом функции, например, Rec (1), вначале записывается состояние предыдущей функции Rec(2) — ее переменная а, значение этой переменной 2 и точка вызова (после которой должна будет выполняться команда whriteln)
И второй важный момент, что в стек записывается не отдельная команда, а функция целиком, состоящая из нескольких команд. Тогда вполне наглядно видно, что функция началась, но не закончилась.
Спасибо огромное! Выручили, сняли камень с души))
Занес сайт в закладки, буду заходить))
а можно еще похожий вопрос, вот есть такой код, стартовое значение 1. Он вроде проще, но там есть одна закавыка
if a<11 then
writeln(a);
Rec(a+1);
Закавыка в том, что вызов функции не входит в тело условия if и тогда получается, что функция будет вызываться снова и снова. Но реально пример работает и выводит последовательность от 1 до 10. Почему функция больше не вызывается?
Функция вызывается, просто больше ничего не печатает.
гм, тогда правильно я понимаю, что функция вызывается бесконечно?
Да, теоретически бесконечно. Практически, либо стек переполнится и программа аварийно завершится, либо «умный» компилятор, поняв, что программа фактически ничего не делает, уберет лишние вызовы.
Спасибо! В принципе об этом говорилось у вас здесь в самом начале, но одно дело когда просто написано, другое — когда сам это реально видишь))
В общем, еще раз — спасибо огромное, что помогли разобраться!
В самом первом примере последовательность выводимых чисел будет равна 3 2 1 0.
В первом примере все зависит от того где в программе будет находится write(a);, т.е. в каком месте.
Лучшая статья про рекурсивны алгоритмы. Как раз подбирал задачки ребёнку для изучения — очень помогло.
Спасибо!
Отличный материал! Буду учить
Спасибо!
gwy9y7
h6btyv