Словарный запас |
 14.07.2016
14.07.2016 |
|
Померил свой словарный запас в английском на testyourvocab.com. Обнаружил, что
Среди носителей языка это соответствует возрасту 10 лет.
Как я еще молод! |


Работа | ||
|
22.09.2011 | ||
|
Египет |
|
17.07.2011 |
 Был, вот. |
Armadillo C++ linear algebra library |
|
06.06.2011 |
|
|
Лысые Горы — Атаевка | |||
|
04.05.2011 | |||
|



Посоревнуемся? |
|
15.04.2011 |
|
Человечество производит и собирает необозримое количество разнообразной информации. Размеры собранных баз данных безнадежно далеко превосходят любые возможности человеческого восприятия. Соответственно развиваются разнообразные методы автоматического поиска интересных закономерностей в существующем океане данных. Для таких задач даже придумали специальные модные термины, такие как Data mining (добыча данных), Knowledge Discovery in Data (извлечение знаний), интеллектуальный анализ данных и т.п. По большей части все это есть ни что иное, как старая добрая статистическая обработка. Так или иначе, разнообразные подходы к анализу накопленных данных очень популярны и несомненно будут активно развиваться. Одним из признаков этого являются многочисленные соревнования, где участникам предоставляется гигабайт-другой каких-нибудь дынных и предлагается что-нибудь наилучшим образом аппроксимировать, классифицировать или предсказать. Поскольку значительная часть дисциплин специализации на нашей кафедре связана с анализом данных, кажется небезынтересным собрать ссылки на такие соревнования. Итак, патриотично начнем с нашего российского конкурса: |
Рекурсия |
|
30.01.2011 |
|
Написался большой учебный текст про рекурсию: |
Books Ngram Viewer |
|
22.12.2010 |
|
Забавный сервис от Google (http://ngrams.googlelabs.com/). Строит графики относительной частоты появления слов в изданных книгах. Более-менее стабильные результаты получаются, начиная с 1800 года. Ну, например, 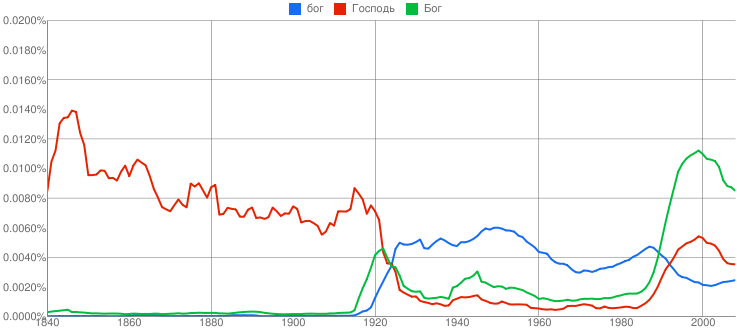 |